VBA Overview
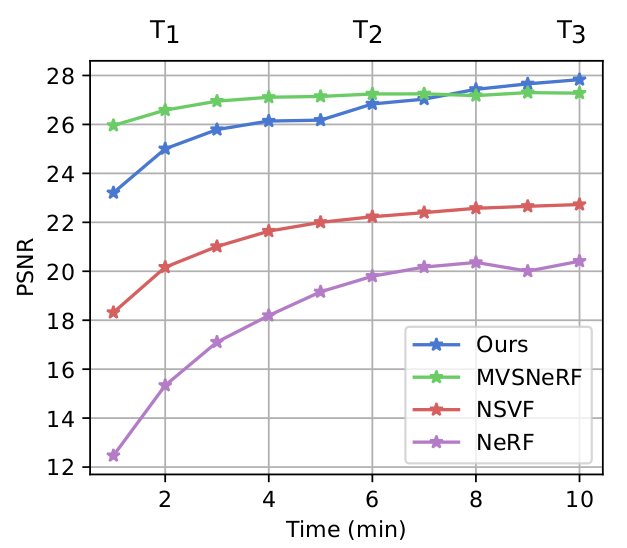
Our contributions are the following,- VDB feature volume: we propose a hierarchical feature volume using VDB grids. This representation is memory efficient and allows for fast querying of the scene information.
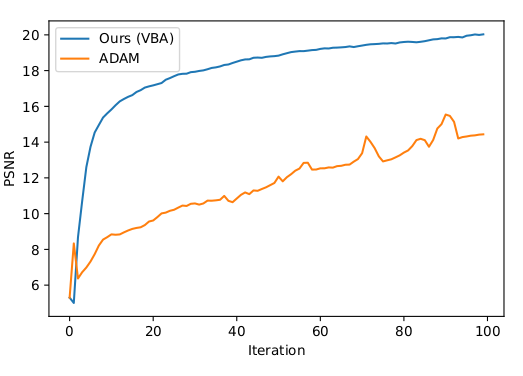
- Approximate second-order optimizer: we introduce a novel optimization approach that improves the efficiency of the bundle adjustment which allows our system to converge to the target camera poses and scene geometry much faster.
Method explanation
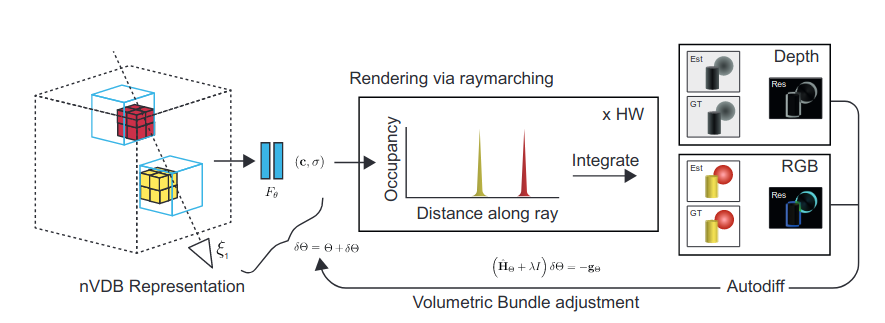
We represent the scene as a neural VDB that stores spatial scene features. These features encode the shape and appearance of the scene in a high-dimensional feature space. Raymarching is used to render views of the volume specified by a camera pose. During rendering the features are sampled from the volume using trilinear interpolation and a shallow MLP is used to project these features to color and occupancy values. The estimated pixel color is computed by integrating the color values along the ray weighted by the occupancy and visibility. This is repeated for each pixel in the image. Once all the rays are rendered, the residuals are computed as the difference between the estimated and ground truth images. The residuals are then minimized using volumetric bundle adjustment (VBA), which efficiently refines the volume and camera pose parameters.